
Claude 3: Benchmarks in Dispute
Claude 3's AI benchmarks stir controversy, igniting debate over its position against GPT-4's established prowess.

Executive Summary
Despite contentious benchmark results, Claude 3 joins GPT-4 and Gemini Pro as a formidable "GPT-4 class" LLM.
Each LLM exhibits unique qualities: Claude 3, the writer, Gemini Pro, the explainer, and GPT-4, as a versatile all-rounder.
Interface and tooling are key differentiators: Gemini is polished, Claude 3 is minimalist, and GPT-4 offers extensive tools.

Claude 3's Debut: A Nuanced Leap in LLMs
The AI world is abuzz with the latest entrant, Claude 3, joining the ranks of GPT-4 and Gemini Pro as a "GPT-4 class" large language model (LLM). Its release by Anthropic has been met with acclaim for its capabilities and scrutiny over benchmark comparisons. As we delve into the fabric of this new AI phenomenon, we explore not just numbers but the very essence that differentiates Claude 3 in the LLM landscape.
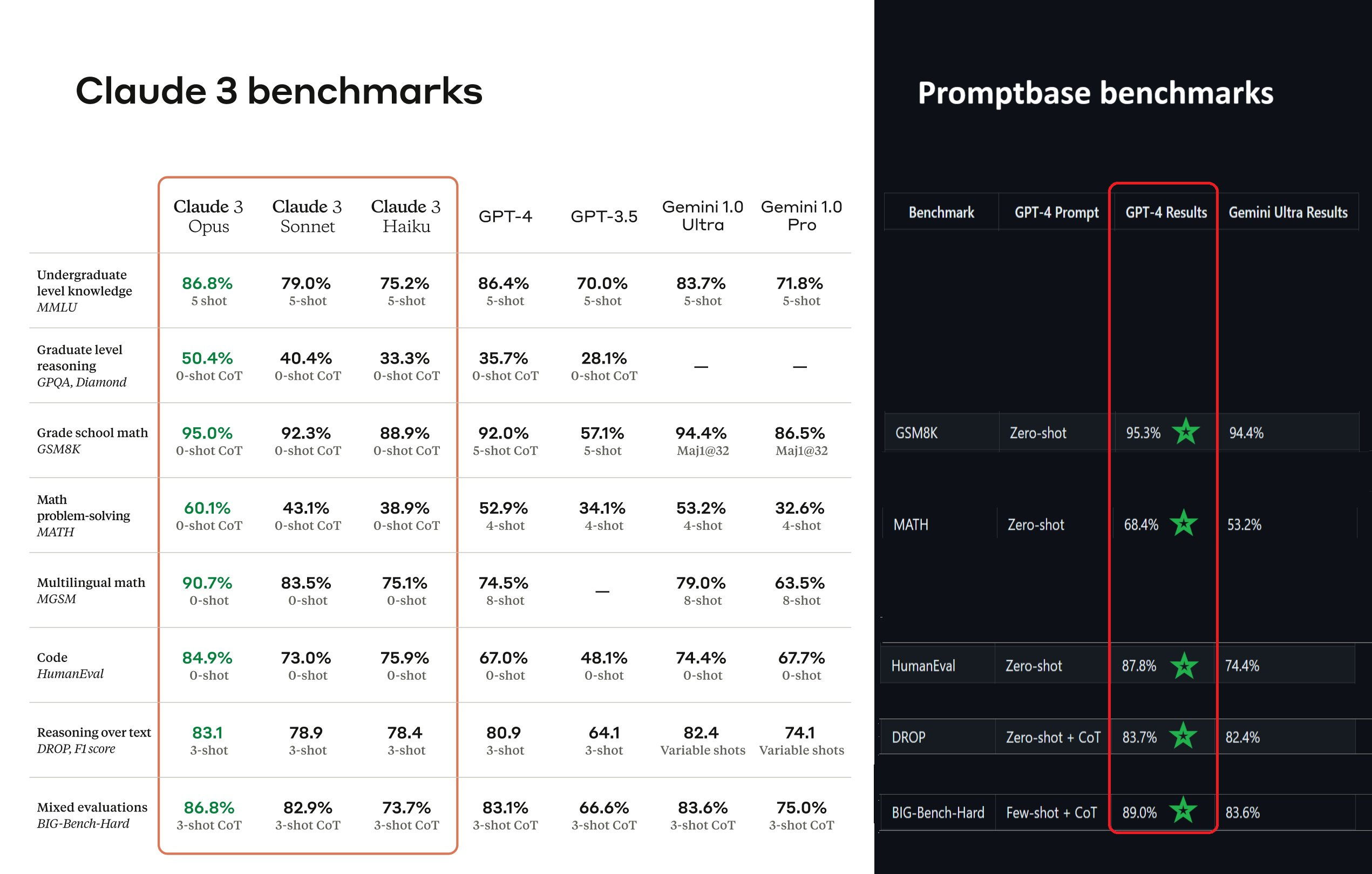
Claude 3's Contested Benchmarks
Anthropic's press release paints a promising picture of Claude 3, with benchmarks suggesting it sets new industry standards in intelligence, speed, and cost. However, these claims have been contested. A footnote in the release acknowledges that while Claude 3's benchmarks compare favourably against commercially available models, engineers have optimised prompts for evaluations, and a newer GPT-4T model reports higher scores.
Beyond Benchmarks: The Texture of Claude 3
Ethan Mollick sheds light on a broader perspective. While all three LLMs prompt similarly and exhibit comparable rates of hallucinations and pedantic tendencies, each brings a distinct "personality" to the table. Claude 3 excels as a writer, showcasing its flair for nuanced content creation, while Gemini Advanced shines as an explainer, and GPT-4 maintains solid all-around performance. This trio also brings varied features, such as context windows and multimodal capabilities, influencing their utility in different domains.
User Experience and Tools: The LLM Ecosystem
The user interface and tool integration further differentiate these models. Gemini boasts a polished interface with intriguing Google integrations, Claude 3 offers a clean, minimalistic user experience, and GPT-4 provides a diverse toolkit with powerful API access. These variations will likely sway users towards the LLM that best fits their workflow and aesthetic preferences.
A Look at the Bigger Picture
As the AI community debates benchmarks, it's essential to recognise the broader implications of Claude 3's arrival. It signifies a maturation in LLMs, where choices abound in performance and the relationship between humans and AI. The "personality" of an LLM, its integration into systems, and its alignment with user needs are becoming just as critical as the scores it achieves on tests.
In the grand narrative of AI, Claude 3's launch is more than a contest of numbers. It represents the evolving complexity and richness of large language models, their role in our digital ecosystem, and their potential to reshape how we interact with technology. While benchmarks provide a snapshot of capability, the true measure of an LLM's value will be written in the experiences it creates and the challenges it overcomes.